Videk a mash-up for environmental intelligence, based on several sources of real data, including data from Smart Objects (sensor nodes), Geonames, Wikipedia, ResearchCyc and Panoramio. It uses stream indexing and mining as well as semantically linked data. It is able to visualize sensor data and their geographical context, it is able to retrieve related information form various external sources and it is able to provide rule-based event detection:
System Architecture
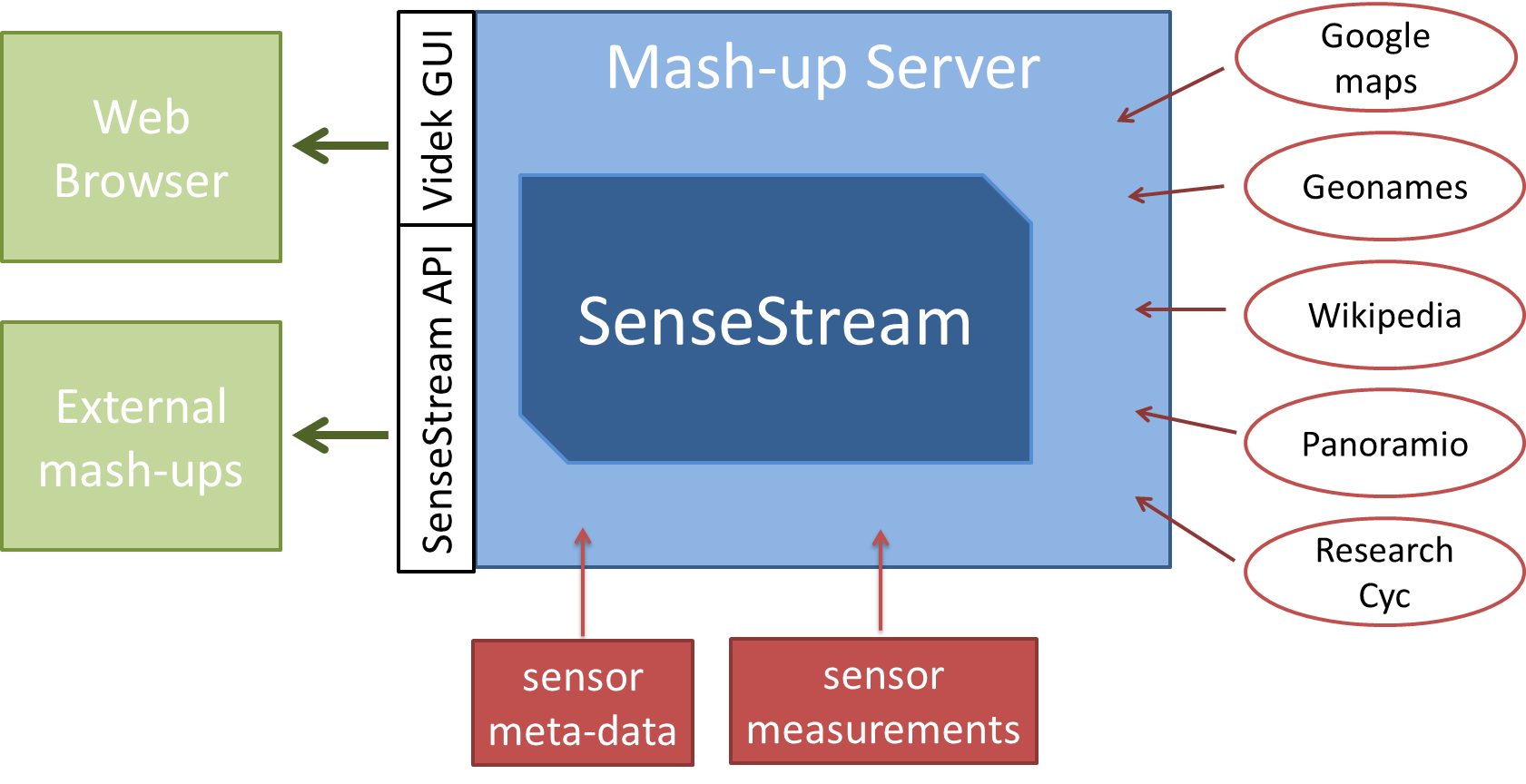
Videk consists of four main components as depicted below: the sensor data, the external sources, the mash-up server and the user interface. The Videk mashup server acts as a glue between different components and services used. It interfaces with sensors receiving data from these, parses and multiplexes the data to the backup database, to SenseStream, to ResearchCyc, and to the triple store. Then it exposes the API to be used by external applications and a GUI with widgets which mashes up the data and resulting knowledge described above.
Mash-up server is built around SenseStream, which is Storing and Stream Processing Engine, which transforms the sensor data into useful information and knowledge.
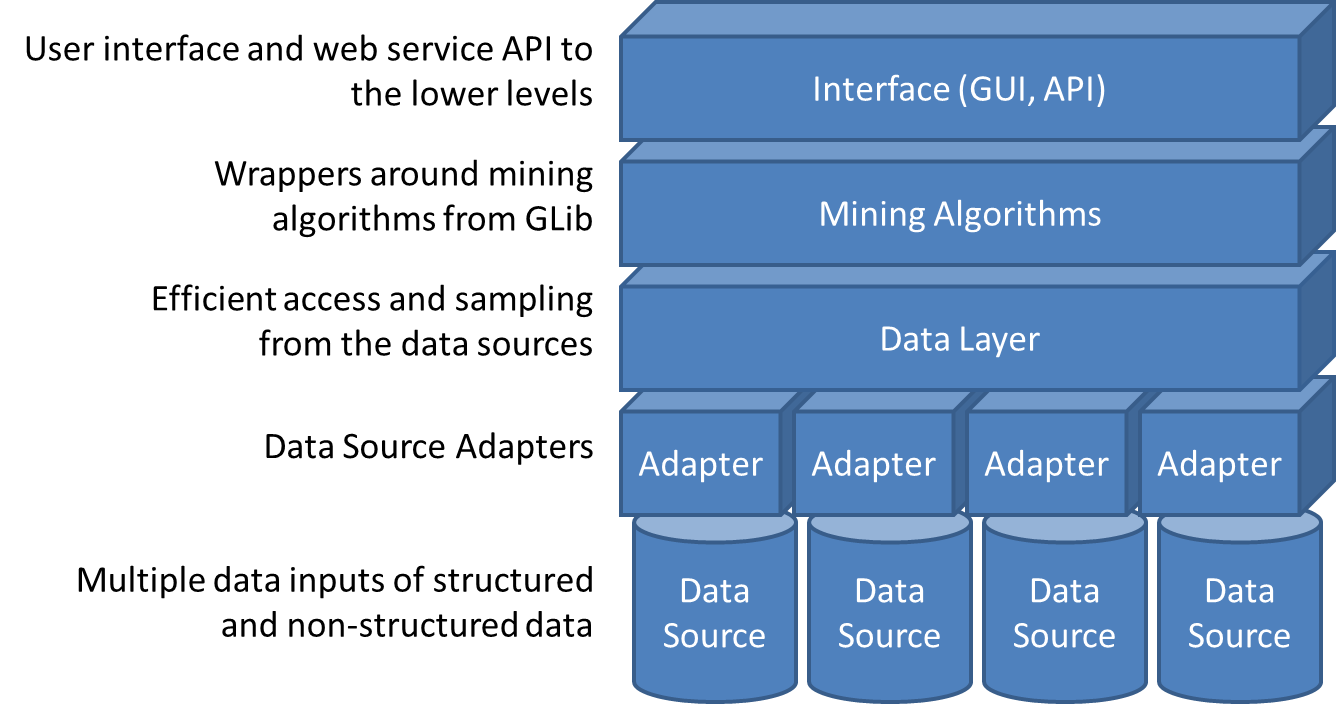
SenseStream is built on the top of QMiner component that is using an internal C++ data mining libraries. The central part of the system consists of two components: Data Layer and Mining Algorithms. At the bottom of the architecture diagram is a set of data sources - sensor meta-data and streams of sensor measurements.
DataLayer in Videk consists of 6 stores as depicted in the picture below: SensorNode, Sensor, SensorType, SensorMeasurement, SensorAggregate and separate Event store.
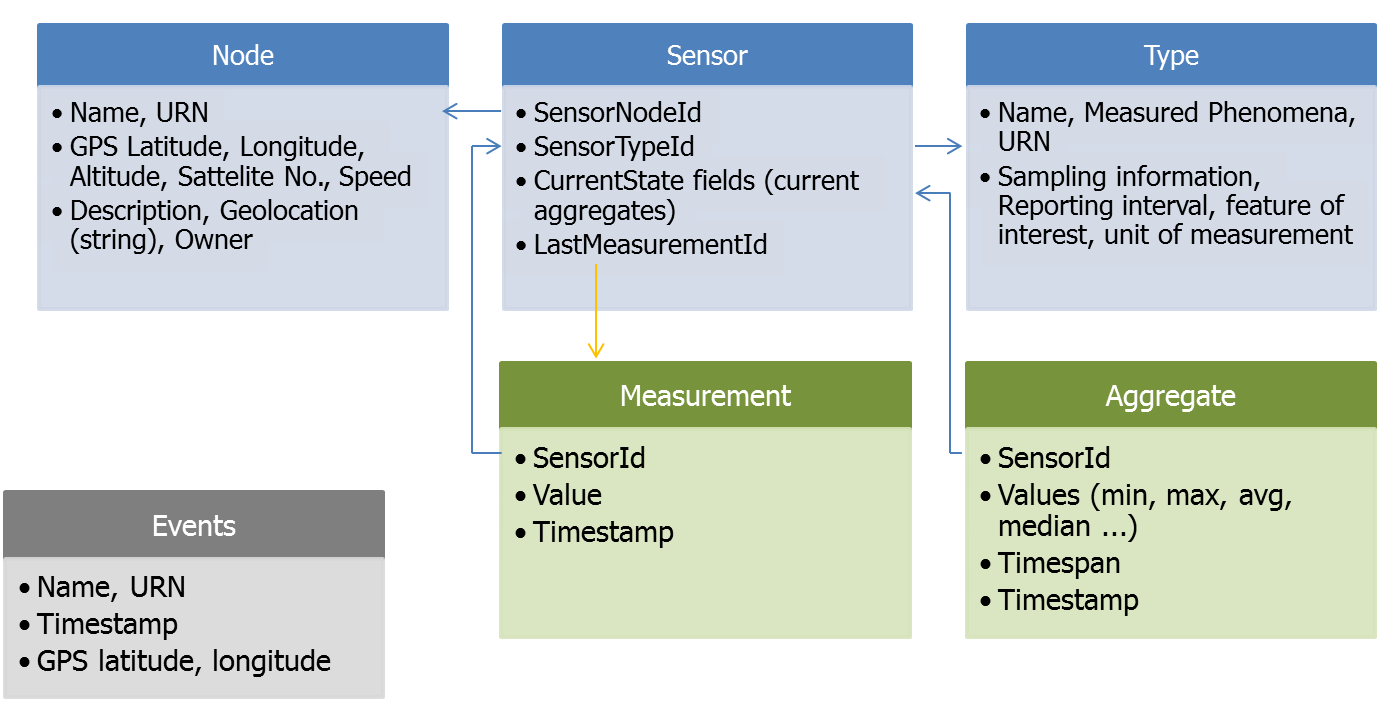
The Data Layer provides unified access to all the data sources from the higher architectural layers, and includes integrated inverted index and multi-modal feature extractors. Integrated inverted index is used to provide faceted search functionality over the records from the data sources. Integrated multi-modal feature extractors provide functionality for extracting feature vectors from raw data provided by the various data sources. Feature extractors provide an abstraction layer required by machine learning algorithms.
The measurement feed is processed in real-time. On arrival, each measurement is put in a FIFO queue, and used to update the running aggregate for various time windows. The size of time windows is provided as input parameters. On specified intervals (e.g. minute, hour, day, week), aggregates are stored in a designated store, and indexed using its value, time, period, aggregation type, measured phenomena and sensor. The SenseStream API offers browsing, querying and mining of all stored measurements and its aggregates. The results can be exported using Linked Data standards (RDF, RuleML).
References:
- Klemen Kenda, Carolina Fortuna, Alexandra Moraru, Dunja Mladnic, Blaž Fortuna, Marko Grobelnik: Mashups for The Web of Things. in: Brigitte Endres-Niggemeyer (ed.) Semantic Mashups. Springer (forthcoming)
- Carolina Fortuna, Blaz Fortuna, Klemen Kenda, Matevz Vucnik, Alexandra Moraru, Dunja Mladenic: Towards Building a Global Oracle: a Physical Mashup Using Artificial Intelligence Technology , Third International Workshop on the Web of Things (co-located with IEEE Pervasive), June 2012
- Klemen Kenda, Carolina Fortuna, Blaž Fortuna, Marko Grobelnik: Videk - A Mash-up For Enviromental Intelligence, ESWC 2011, May 2011