| Enrycher DEMO Enrycher JAVA API |
Enrycher is a service-oriented system, providing shallow as well as deep text processing functionality at the text document level.
Shallow text processing:
- topic and keyword detection
- named entity extraction: names of people, locations and organizations, dates, percentages and money amounts
Deep text processing:
- named entity resolution with respect to existing Linked datasets: DBpedia, YAGO, OpenCyc
- named entity merging: co-reference and anaphora resolution
- word sense disambiguation into WordNet
- assertion extraction, by identifying subject – predicate – object sentence elements together with their modifiers (adjectives, adverbs) and negations
Enrycher Services
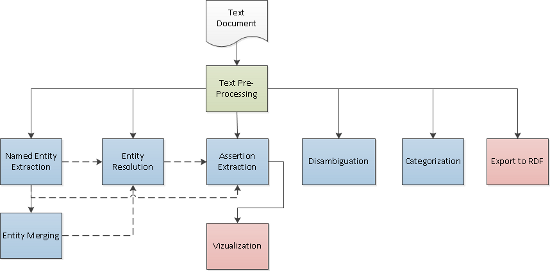
The Fact Extraction Service is composed of 9 services, depicted in the figure below. The services are grouped in 3 types: Enrycher Pre-processing Services, marked in green, Enrycher Extraction Services marked in blue and Enrycher Transformation Services marked in red. The figure shows the dependencies between services, some of them mandatory (depicted with a filled line), some optional (depicted with a dashed line). All services rely on a text pre-processing step handled within the Text Pre-Processing Service, and consisting of sentence splitting and tokenization.
Example Calls
The Enrycher Web Service API exposes each service functionality.
In order to call the Enrycher services, we provide the following URLs:
- for XML output: enrycher.ijs.si/run
- for RDF output: enrycher.ijs.si/run-rdf
To execute the service, one should send an HTTP POST request, with the raw text in the body:
| curl -d "Enrycher was developed at JSI, a research institute in Ljubljana. Ljubljana is the capital of Slovenia." http://enrycher.ijs.si/run |
The Java API for calling the Enrycher services can be now found on GitHub.
Publications
- ŠTAJNER, Tadej, RUSU, Delia, DALI, Lorand, FORTUNA, Blaž, MLADENIĆ, Dunja, GROBELNIK, Marko. A service oriented framework for natural language text enrichment. Informatica (Ljublj.), 2010, vol. 34, no. 3, 307-313.
- ŠTAJNER, Tadej, MLADENIĆ, Dunja. Entity resolution from texts using statistical learning and ontologies. In Proceedings of the 4th Asian Conference on The Semantic Web, 2009, 91-104.
- RUSU, Delia, FORTUNA, Blaž, MLADENIĆ, Dunja, GROBELNIK, Marko, SIPOŠ, Ruben. Document visualizayion based on semantic graphs. In Proceedings : Information Visualization, IV 2009, 15-17 July 2009, Barcelona, Spain. 292-297.
- RUSU, Delia, FORTUNA, Blaž, GROBELNIK, Marko, MLADENIĆ, Dunja. Semantic graphs derived from triplets with application in document summarization. Informatica (Ljublj.), 2009, vol. 33, no. 3, 357-362.
- ŠTAJNER, Tadej: From unstructured to linked data: entity extraction and disambiguation by collective similarity maximization. In Identity and Reference in web-based Knowledge Representation (IR-KR): Proceedings of the IJCAI-09 workshop, 29-34.
- RUSU, Delia, LORAND, Dali, FORTUNA, Blaž, GROBELNIK, Marko, MLADENIĆ, Dunja. Triplet extraction from sentences. In Proceedings of the 10th International Multiconference Information Society 2007, 218-222.
- GROBELNIK, Marko, MLADENIĆ, Dunja. Simple classification into large topic ontology of web documents. CIT. Journal of Comput. Inf. Technol., 2005, vol. 13, 279-285.